

There Is No Best Agent — Only the Best Agent for Your Codebase
The agent that looks “best” on leaderboards will not be the “best” on every codebase.
Across four real-world codebases:
- Accuracy varies by up to 40 percentage points between agents
- Consistency varies by up to 50 percentage points, often in a different order to accuracy
- Speed differs by more than 4x, with a clear leader
- No single agent leads everywhere
The Agents We Compared
We compared the following coding agents (combinations of harness and large language model):
- Cursor CLI (Composer-1)
- Codex CLI (GPT-5.1-Codex-Max)
- Claude Code (Opus 4.5)
- Gemini CLI (Gemini 3 Pro Preview)
What We Measured
For this analysis, we focused on 4 of the 60 open-source codebases of the Sigmabench dataset: Cloudflare DDNS, SmartDoc, Webpack, and ScrapeGraphAI.
Each agent was measured on:
- Speed — how quickly tasks are completed
- Accuracy — how often outputs meet quality thresholds
- Consistency — how often outputs remain useful even when not fully completing a task
Same agents. Different codebases. We’ve used the same methodology as the Sigmabench leaderboard, using 15 commits per codebase. In order to improve the margin of error on each metric, we ran each agent 5 times for each commit.
The Winners Change by Codebase
To make this concrete, the table below shows which agent performs best on each codebase for speed, accuracy, and consistency.
Winners by Codebase:
What this shows at a glance:
- Speed has a consistent leader
- Accuracy leadership changes by codebase
- Consistency leadership also changes by codebase
- No single agent dominates across all dimensions
This is why a single global leaderboard is misleading.
Accuracy Swings the Most
Accuracy shows the largest performance swings across codebases.
The same agent can rank #1 for accuracy on one codebase and last on another, using the same model version and evaluation method.
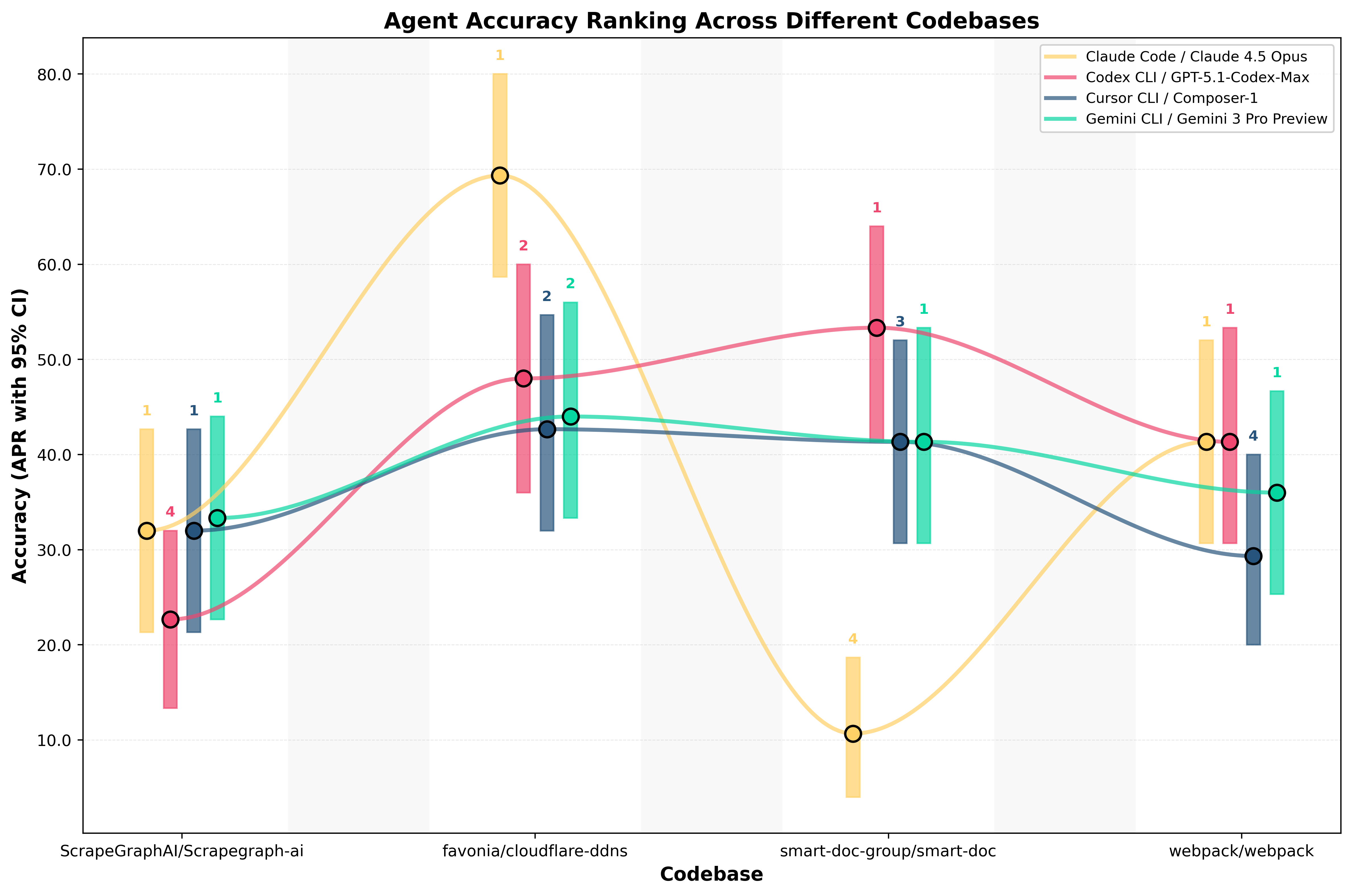
Examples from the data:
- Claude: Most accurate on Cloudflare DDNS, but least accurate on SmartDoc.
- Codex: Most accurate on SmartDoc, yet falls behind Claude and Gemini on Cloudflare DDNS.
- Cursor: Competitive on ScrapeGraphAI, but the least accurate agent on Webpack.
- Gemini: Accuracy leader on ScrapeGraphAI, with mid-tier performance elsewhere.
These are not marginal shifts. They are rank reversals.
Consistency Tells a Different Story
Consistency behaves independently of accuracy and reveals a second source of variation.
While accuracy measures peak correctness, consistency reflects how an agent’s outputs remain useful even when not fully completing a task — a critical factor in real development workflows.
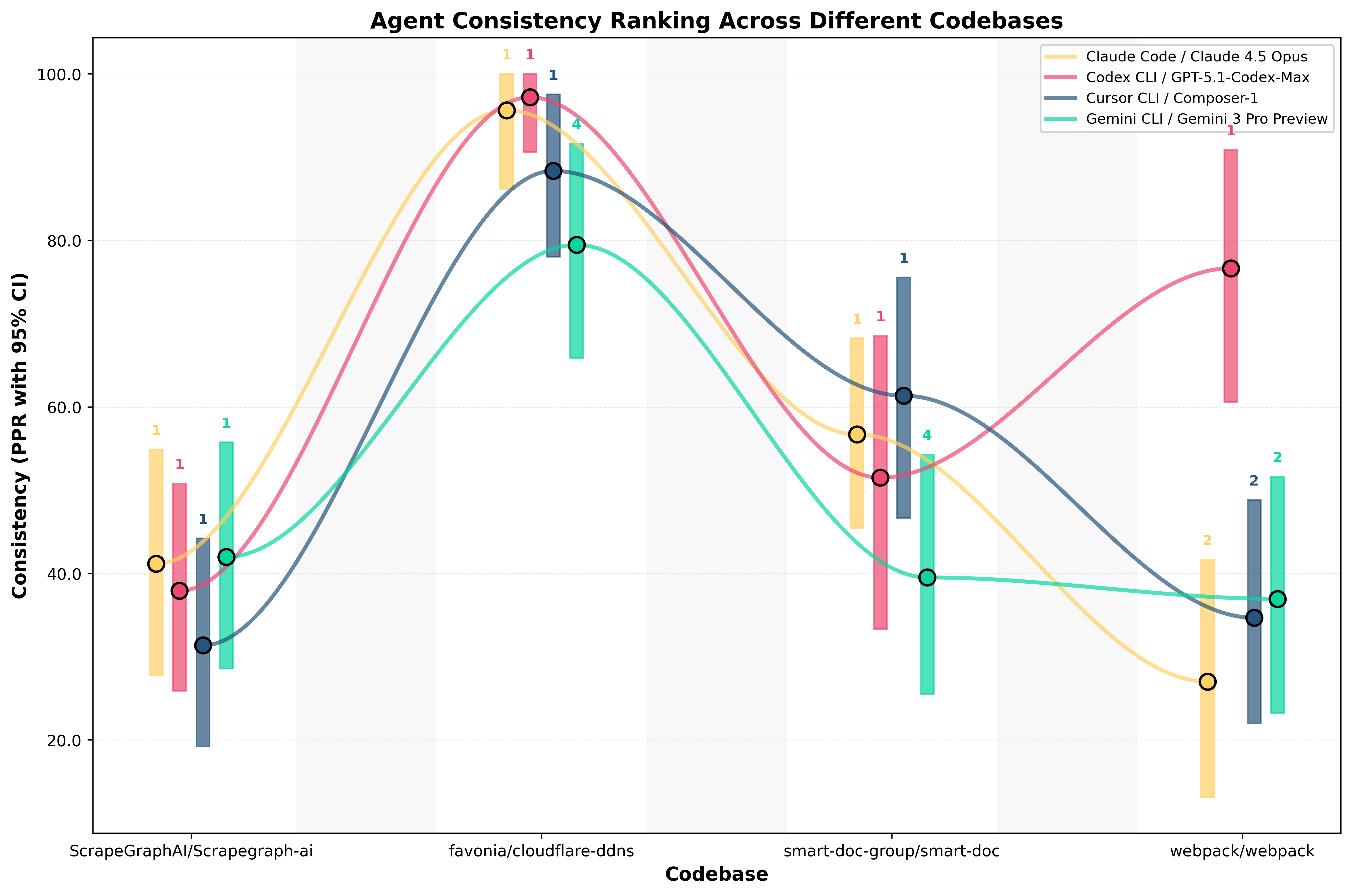
What we see across codebases:
- Gemini: Most accurate (although within the margin of error) on ScrapeGraphAI, clearly last on Cloudflare DDNS and SmartDoc, and second-tier on Webpack, showing the largest consistency swing across codebases.
- Codex: Generally top-tier across codebases, and by far the most consistent agent on Webpack.
- Cursor: Top-tier on Cloudflare DDNS and SmartDoc, but drops to second-tier on Webpack.
- Claude: Top-tier on ScrapeGraphAI, Cloudflare DDNS, and SmartDoc, but falls to second-tier on Webpack.
Consistency varies dramatically by codebase. Agents can rank from first to last depending on the repository, and consistency rankings do not track accuracy rankings.
Speed Is Stable — But Not the Decider
Speed is the most stable metric across codebases.
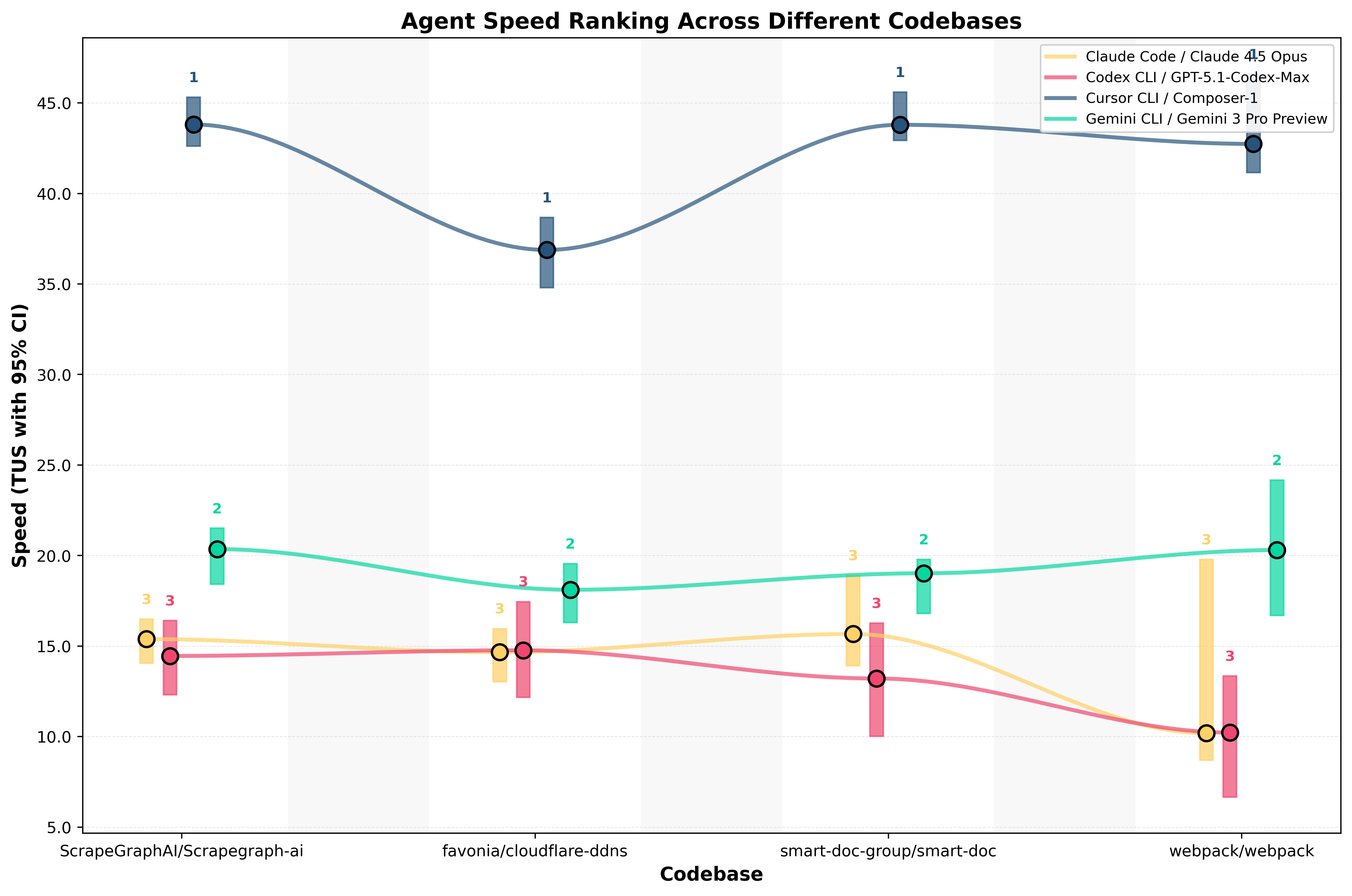
Across all four:
- Cursor is consistently the fastest agent
- Often 4× faster than Claude, Gemini, and Codex
The Takeaway
There is no best coding agent. However, there is:
- the best agent for your codebase
- for your priorities
- measured against your constraints
Any benchmark that ignores this context is incomplete.
What This Means for Teams
If you’re choosing a coding agent based on a global leaderboard:
- you may be optimizing for the wrong metric
- or selecting an agent that performs poorly on your codebase
The only reliable way to choose is to benchmark your own codebase.