1. Executive Summary
1.1 What this benchmark answers
Which coding agent delivers the strongest real-world performance on your codebase, accounting for
accuracy, consistency, and speed?
Using statistically rigorous benchmarking on your selected repository, this report identifies which coding agents
are best-in-class for your specific codebase, rather than relying on generic or one-size-fits-all benchmarks.
1.2 Key takeaways
Best overall agent
Cursor CLI + Composer 1 is the clear Tier 1 performer by Sigmascore, making it the most well-rounded agent on the
democorp/admin-portal repository.
Accuracy leader
Codex CLI + GPT-5.1 Codex Max achieves the highest median Accuracy overall.
Cursor CLI is not far behind, technically Tier 1 also but very likely to be less accurate on average.
Speed dominance
Cursor CLI is dramatically faster than all alternatives, averaging ~6x faster execution than the next best agent on your codebase. This speed advantage dramatically enhances productivity in interactive
workflows. For asynchronous or automated workflows this advantage is less critical.
Steep Performance/Speed Tradeoff
Codex CLI + GPT-5.1 Codex Max offers the best Accuracy and exceptional Consistency on your codebase but it
is also by far the slowest agent in this evaluation.
Better Performance than the Global Leaderboard
The democorp/admin-portal repository appears particularly well-suited to agentic coding; we've
observed stronger performance from virtually all agents across all metrics compared to the global Sigmabench
leaderboard.
1.3 Why this benchmark matters over time
This benchmark should be viewed as a point-in-time measurement, not a static verdict.
Agentic coding performance is sensitive to:
model and agent releases,
repository evolution,
and—critically—how agents are configured, instructed, and contextualized within your organization.
evaluate new model or agent versions as they are released,
measure the impact of internal agentic best practices,
and track whether your organization's use of coding agents is improving, stagnating, or regressing.
1.4 Recommended actions
Primary recommendation
Cursor CLI + Composer 1
Best-in-class overall performance, unmatched speed, and consistent Tier 1 results make this the default recommendation
for most use cases.
Secondary recommendation (accuracy-first option)
Codex CLI + GPT-5.1 Codex Max
Recommended when maximum accuracy is prioritized over speed and iteration latency.
Decision guidance by priority
Speed-sensitive workflows: Cursor CLI + Composer 1 (strongly recommended)
Every day use: Cursor CLI + Composer 1
Asynchronous workflows: Codex CLI + GPT-5.1 Codex Max
Accuracy-sensitive work: Codex CLI + GPT-5.1 Codex Max
1.5 How to use this report
Begin with Section 3: Benchmark Results to identify Tier 1 agents using confidence-aware tiers.
Make decisions based on tiers, not raw scores.
Use commit- and run-level analyses (available in the archive that accompanies this report) to audit results, understand failure modes, or support internal decision-making.
2. Benchmark Overview
This section describes what was benchmarked, how it was selected, and which agent-model combinations were evaluated, providing the necessary context to interpret the results in later sections.
This benchmark and document were run and prepared in accordance with the Sigmabench benchmark methodology v1
(December 2025). All versions of our benchmark methodology are specified in detail on our website, see
https://sigmabench.com/methodology.
2.1 Repository & Commits
This benchmark evaluated coding agents on the democorp/admin-portal repository.
Repository Stats
Size: ~60k LOC, ~30k commits
Primary Language: JavaScript
Description: Web-based administrative interface for internal DemoCorp teams.
Commit Selection
We selected the following:
15 representative feature-development commits
Focused on meaningful, non-trivial changes that reflect day-to-day engineering work
Selection Criteria
Commits were chosen using a combination of automated filtering and human review, with the
following constraints:
Bias toward recent development activity
Inclusion limited to regular feature development
Explicit exclusion of:
Large refactors
File renames or moves
Formatting-only changes
Non-code changes (documentation, configuration-only updates)
Each selected commit represents a task that a human developer plausibly might ask an AI coding agent to implement.
2.2 Agents & Models Tested
The benchmark evaluated four agent-model combinations, selected to reflect a cross-section of widely used
modern coding agents.
| Agent | Version | Model |
|---|---|---|
| Cursor CLI | 2025.11.25-d5b3271 | Composer 1 |
| Gemini CLI | 0.21.1 | Gemini 3 Pro (Preview) |
| Codex CLI | 0.63.0 | GPT-5.1 Codex Max |
| Claude Code | 2.0.56 | Opus 4.5 |
Configuration notes
All agents were run using their default configurations
Reasoning / thinking modes (where applicable) were left unchanged from agent defaults
No prompt engineering, custom system instructions, or manual tuning was applied
Agent design choices
Default reasoning strategies
Model-agent integration quality
2.3 Benchmark metrics (high-level overview)
Sigmabench evaluates coding agents across three orthogonal performance dimensions, designed to jointly capture
real-world usefulness rather than optimizing for a single metric.
Accuracy
Measures how often an agent successfully completes the requested change.
A run is considered successful if the generated code meaningfully matches the reference implementation.
Consistency
Computed only over failed runs.
Rewards partial correctness and relevant intermediate work.
Distinguishes between agents that fail “usefully” vs irrelevant/misleading output.
Speed
Measures how quickly an agent produces results.
Based on proportion of the maximum allowed execution time used.
Faster agents score higher, all else equal.
Captures iteration speed and developer feedback latency.
Log-scaled because speed differences are better interpreted in multipliers (x2, x10), not in absolute deltas.
Sigmascore (Composite)
Unweighted geometric mean of Accuracy, Consistency, Speed.
Strong performance requires balance across all dimensions.
Severe weakness in any one area materially lowers the overall score.
No single metric can dominate the final ranking.
Strong performance requires balance across all dimensions.
Severe weakness in any one area materially lowers the overall score.
No single metric can dominate the final ranking.
3. Benchmark Results
3.1 Sigmascore Leaderboard
The chart and table below rank coding agents by median Sigmascore, our composite measure of
accuracy, consistency, and speed.
Enlarge
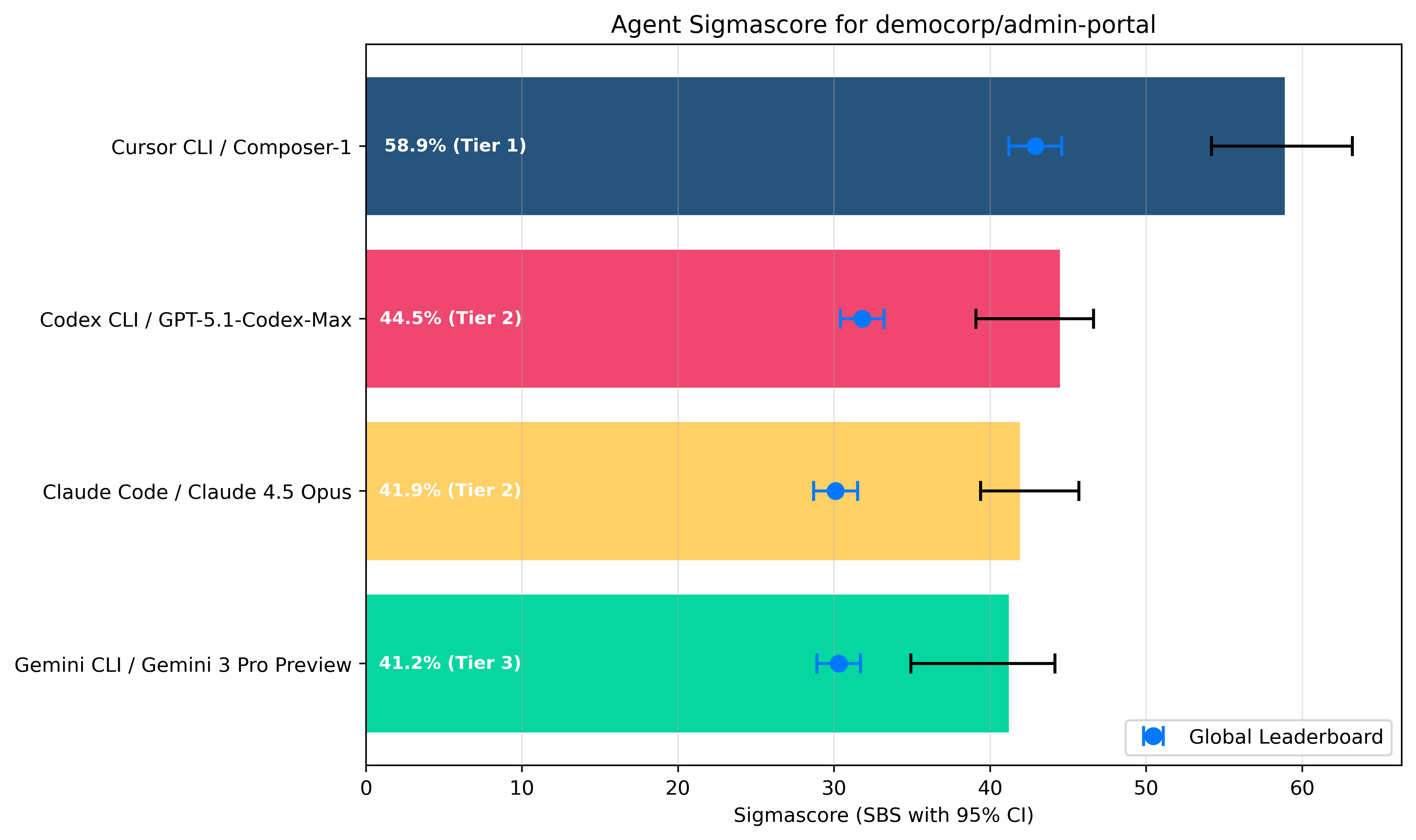
| Tier | Agent | Model | Sigmascore | 95% CI |
|---|---|---|---|---|
| 1 | Cursor CLI | Composer 1 | 58.9% | +/- 4.5 |
| 2 | Codex CLI | GPT-5.1 Codex Max | 44.5% | +/- 3.7 |
| 2 | Claude Code CLI | Claude Opus 4.5 | 41.9% | +/- 3.2 |
| 3 | Gemini CLI | Gemini 3 Pro (Preview) | 41.2% | +/- 4.6 |
Key takeaways
Cursor CLI / Composer 1 is the most well-rounded agent/model combo on your codebase.
Codex CLI / GPT 5.1 Codex Max technically shares Tier 2 status with Claude Code / Opus 4.5 but is very likely to be superior on average on your codebase.
Gemini CLI ranks dead last in this evaluation. Despite strong performance on global leaderboards, Gemini CLI is not the best agent for your codebase.
All tested agents perform significantly better on your repository than the Sigmabench global leaderboard average. This point to your codebase being particularly well-suited for agentic coding.
3.2 Accuracy Leaderboard
The chart and table below rank coding agents by median Accuracy score, indicating each
agent's ability to complete coding tasks success fully end to end.
Enlarge
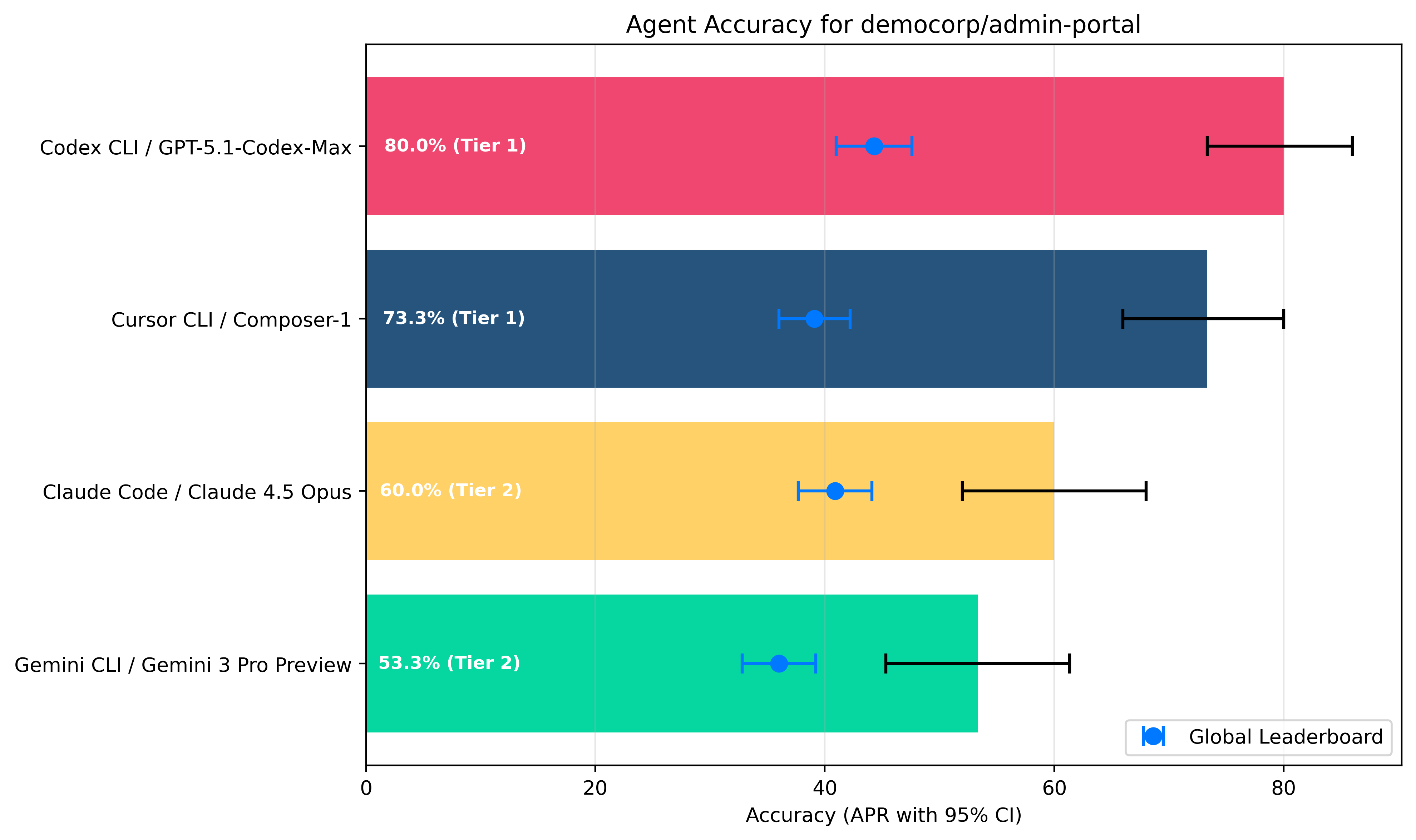
| Tier | Agent | Model | Accuracy | 95% CI |
|---|---|---|---|---|
| 1 | Codex CLI | GPT-5.1 Codex Max | 80.0% | +/- 6.3 |
| 2 | Cursor CLI | Composer 1 | 73.3% | +/- 7.0 |
| 3 | Claude Code CLI | Claude Opus 4.5 | 60.0% | +/- 8.0 |
| 3 | Gemini CLI | Gemini 3 Pro (Preview) | 53.3% | +/- 8.0 |
Key takeaways
Codex CLI / GPT-5.1 Codex Max is the definite accuracy leader on your codebase.
Cursor CLI / Composer 1 holds up surprisingly well, occupying a Tier 1 spot but still very likely behind Codex, and outperforming models that are much slower.
Cursor CLI / Composer 1 significantly over performs on your codebase compared to its results on the Sigmabench global leaderboard. This is great news for DemoCorp: the fastest agent/model combination is also quite accurate on your codebase.
Gemini CLI and Claude Code both significantly underperform in this category. Important note: timeouts are classified as unsuccessful runs, which lowers the Accuracy score. Our timeout is set at 20 minutes.
3.3 Consistency Leaderboard
The chart and table below rank coding agents by median Accuracy score, indicating each
agent's ability to complete coding tasks success fully end to end.
Enlarge
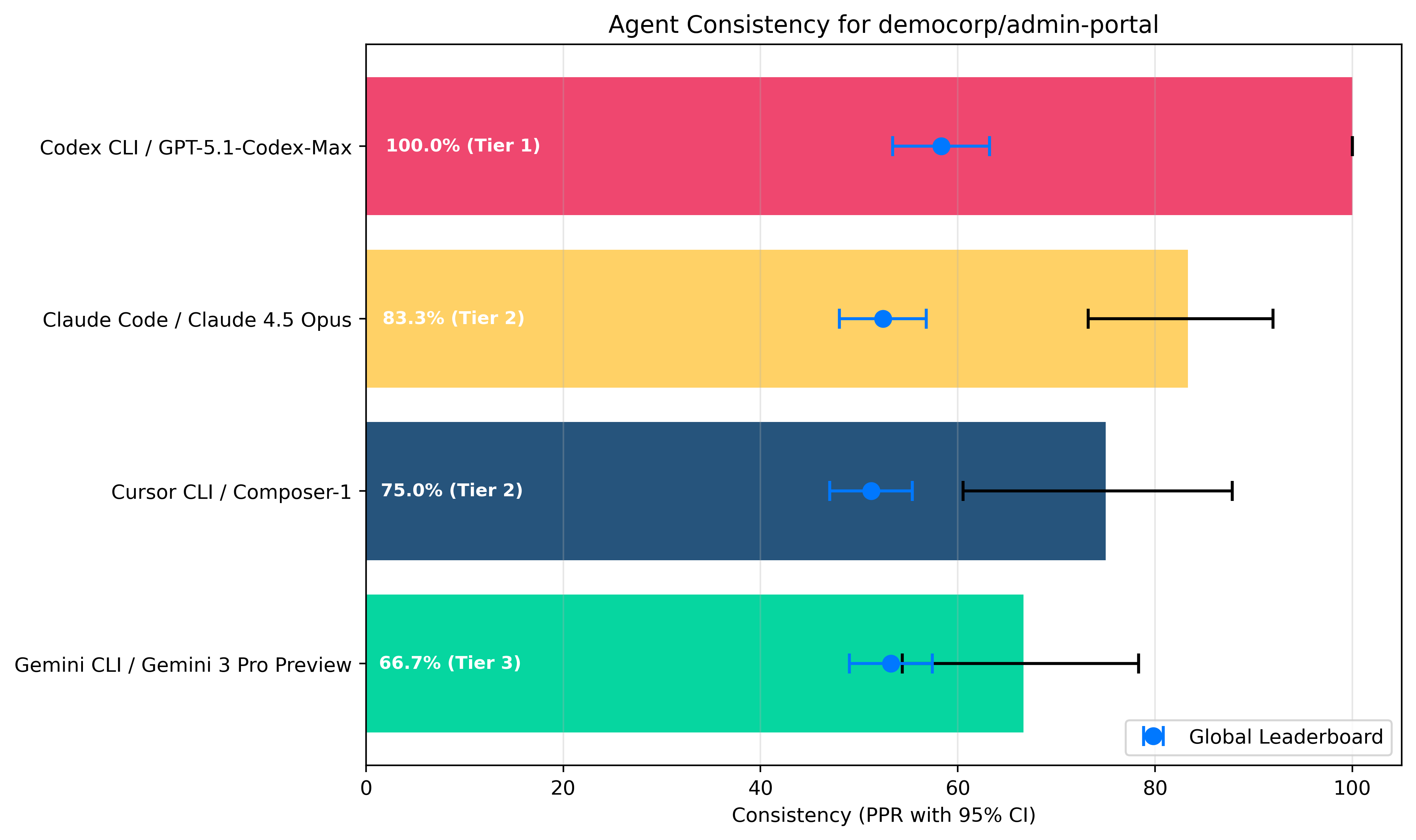
| Tier | Agent | Model | Consistency | 95% CI |
|---|---|---|---|---|
| 1 | Codex CLI | GPT-5.1 Codex Max | 100% | +/- 0.0 |
| 2 | Claude Code CLI | Claude Opus 4.5 | 83.3% | +/- 9.4 |
| 2 | Cursor CLI | Composer 1 | 75.0% | +/- 13.5 |
| 3 | Gemini CLI | Gemini 3 Pro (Preview) | 66.7% | +/- 12.0 |
Key takeaways
Codex CLI / GPT-5.1 Codex Max gets a perfect score in this category. This means that this agent/model combination produced an output that was at least partially useful on every task it was given, which is exceptional.
Cursor CLI / Composer-1 has average performance here, occupying a Tier 2 spot but very likely behind both Claude Code and Codex.
Gemini CLI / Gemini 3 Pro (Preview) again ranks dead last here, confirming the observation that this agent/model combination significantly underperforms on your codebase. Again we're seeing vastly better average consistency scores across all agents
Again we're seeing vastly better average consistency scores across all agents when comparing to the global Sigmabench leaderboard.
3.4 Speed Leaderboard
The chart and table below rank coding agents by median Speed score, indicating how quickly
each agent completes a task. Note that the Speed score is log-scaled. To convert the speed score into a
runtime in seconds, use the formula below.
Enlarge
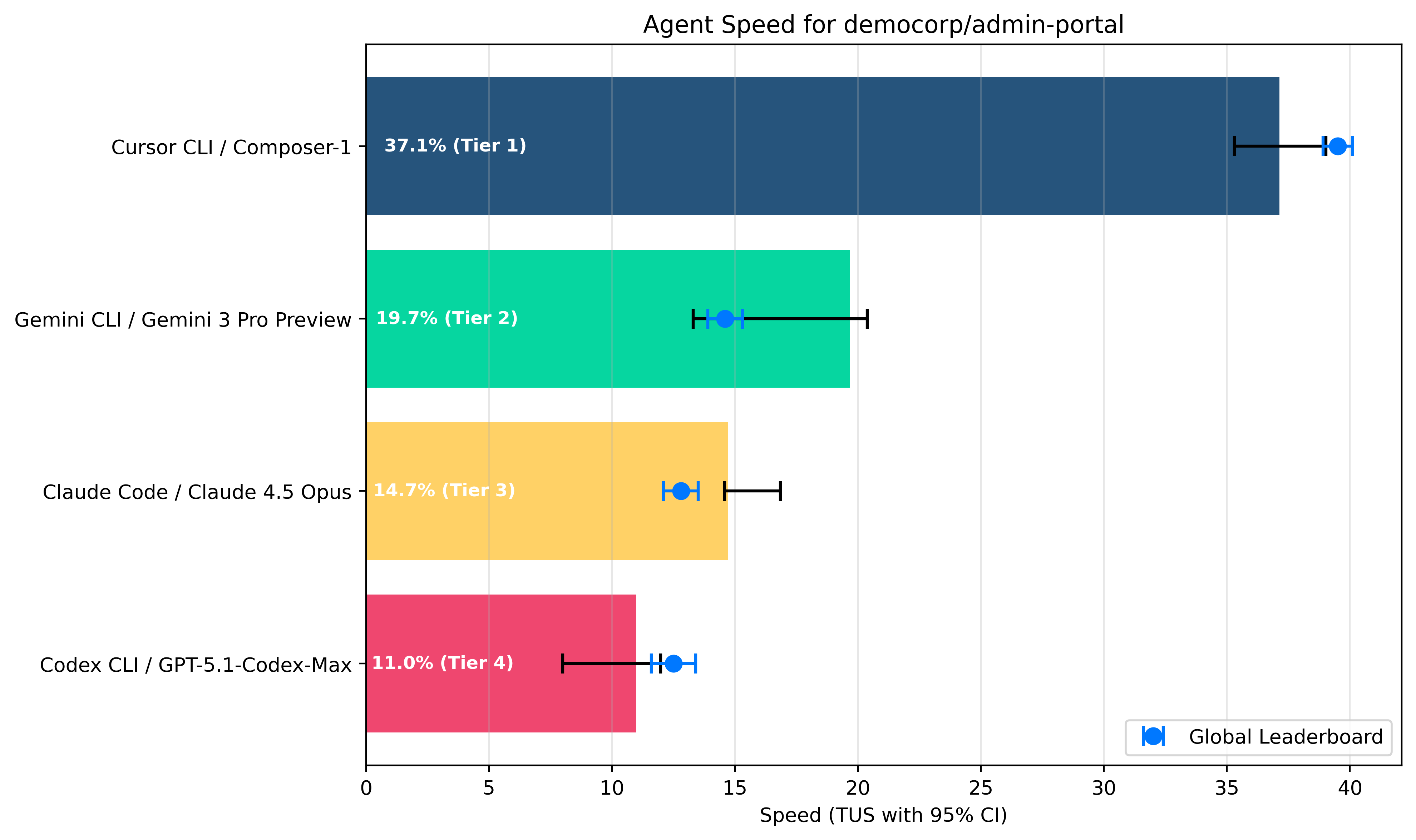
| Tier | Agent | Model | Median Runtime | Speed Score | 95% CI |
|---|---|---|---|---|---|
| 1 | Cursor CLI | Composer 1 | 86s | 37.1% | +/- 1.9 |
| 2 | Gemini CLI | Gemini 3 Pro (Preview) | 297s (~3x Cursor) | 19.7% | +/- 3.5 |
| 3 | Claude Code CLI | Claude Opus 4.5 | 423s (~5x Cursor) | 14.7% | +/- 1.1 |
| 4 | Codex CLI | GPT-5.1 Codex Max | 550s (~6x Cursor) | 11.0% | +/- 2.0 |
Key takeaways
Cursor CLI / Composer 1 runs circles around its competitors in terms of speed. Its median execution time was only 86s, about 6x faster than Codex CLI / GPT-5.1 Codex Max at 550s.
There seems to be a slight decrease in speed on your codebase for both Cursor CLI / Composer 1 and Codex CLI / GPT-5.1 Codex Max but its within a single margin of error difference so it is quite minor.
The other agents exhibit a range of different speeds on your codebase, with Gemini CLI / Gemini 3 Pro (Preview), Codex CLI / GPT-5.1 Codex Max being the slowest, and Claude Code CLI / Claude Opus 4.5 being in the middle of the two.
4. Timeouts & Errors
The table below contains summary of the timeouts and runtime errors encountered when running the Sigmabench
benchmark on your codebase. A comprehensive list of errors and timeouts is available in the archive that
accompanies this report.
| Agent | Model | Successes | Timeouts | Errors |
|---|---|---|---|---|
| Cursor CLI | Composer-1 | 150 | 0 | 0 |
| Codex CLI | GPT-5.1-Codex-Max | 140 (93.3%) | 10 (6.7%) | 0 |
| Claude Code | Claude 4.5 Opus | 150 | 0 | 0 |
| Gemini CLI | Gemini 3 Pro Preview | 140 (93.3%) | 10 (6.7%) | 0 |
Important notes
The benchmark timeout is fixed at 1,200 seconds (20 minutes).
An error can mean one of the following:
the agent returned with a non-zero exit status;
the agent produced no source-code changes.
Key takeaways
Timeouts are counted negatively towards Accuracy. The fact that Codex CLI / GPT-5.1-Codex-Max is the clear Accuracy winner despite timing out ~7% of the time is a testament to its excellent performance on your codebase.
No runtime errors occurred during the running of this benchmark (or if they did, they were deemed retry-able and ended up succeeding). This means that the results contained in this document are not affected by execution issues, and reflect genuine differences in agent performance rather than artifacts of miscellaneous failures.
Confidentiality & Copyright Notice
Confidentiality
This report and all information contained herein are confidential and proprietary. It has been prepared exclusively
for DemoCorp and is provided solely for internal evaluation and decision-making purposes.
This document may not be disclosed, distributed, reproduced, or otherwise made available, in whole or in part, to
any third party without the prior written consent of Simabench, except as required by applicable law.
Copyright
© 2026 Sigmabench, a venture of DevRamp Limited. All rights reserved.
The intellectual property, methodologies, benchmarking frameworks, scoring systems, analyses,
and presentation contained in this report remain the exclusive property of Simabench. No license or right is
granted to use, reproduce, or commercialize any portion of this material beyond the internal use for which it
was provided.